Data science pipeline
- 16 minsData science pipeline
Data science pipeline có thể được hiểu là luồng liên kết nhiều thành phần khác nhau, data được vận chuyển qua từng bước để tạo thành một quy trình xử lý từ đầu đến cuối. Một pipeline cơ bản có thể được tổ chức gồm các bước sau:
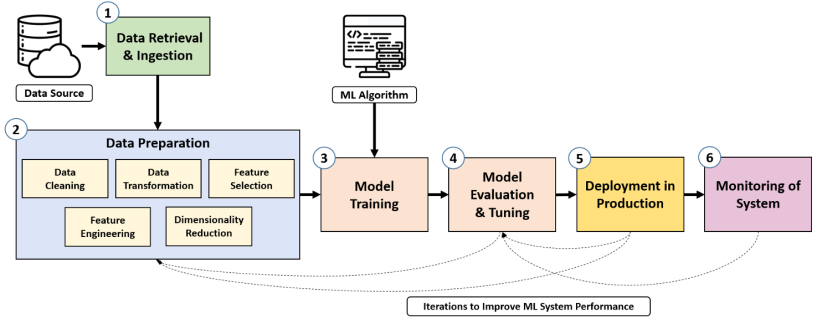
- Data retrieval and ingestion: Data là thành phần quan trọng nhất của các project. Bước đầu tiên trong pipeline sẽ thu thập dữ liệu từ các nguồn khác nhau để đưa vào project. Dữ liệu cần được nhận dạng từ các nguồn, kiểu dữ liệu là gì, thông tin cần lấy, lưu trữ tập trung dữ liệu thu thập được vào một kho tập trung để gửi đến bước tiếp theo trong pipeline.
- Data preparation: Để mô hình đạt được độ chính xác, dữ liệu cần phải được xử lý. Bước chuẩn bị dữ liệu bao gồm việc áp dụng các kĩ thuật như classification, cleaning, transformation, feature selection và feature engineering.
- Model training: Sau khi dữ liệu đã được thu thập và xử lý để chọn lọc ra các thông tin quan trọng nhất, các model có khả năng giải quyết bài toán sẽ được training với dữ liệu này.
- Model evaluation and tuning: Khi model được training xong, cần được đánh giá độ chính xác bằng các độ đo và tinh chỉnh model (theo dữ liệu, hyperparameters, chọn model phù hợp)
- Model development: Sau khi đánh giá, tinh chỉnh hoàn tất, model tốt nhất được chọn. Lúc này model cần được deploy hay còn gọi là serving, đây là bước tích hợp model vào sản phẩm thật để đưa ra các dự đoán.
- Monitoring: Đây là bước cuối cùng đảm bảo model sau khi đưa vào vận hành đáp ứng được chất lượng yêu cầu. Các vấn đề cần được kiểm tra, giám sát liên tục như độ chính xác của model (có thể thay đổi theo thời gian do dữ liệu thay đổi), chất lượng dữ liệu, tài nguyên xử dụng (ram, cpu, gpu,…)
Tại sao cần xây dựng data pipeline
Mỗi bước trong pipeline ở trên đều chịu trách nhiệm riêng của mình. Việc xây dựng pipeline giúp tự động hóa quy trình triển khai model từ lúc có dữ liệu thô đến khi ra được model thành phẩm đưa vào dự đoán bài toán thực tế. Pipeline này giúp giảm thời gian triển khai các bước lặp đi lặp lại: Nhận dữ liệu -> xử lý -> training -> serving -> nhận dữ liệu mới ->… DS có thể tập trung vào cải thiện từng step. Trường hợp cần cải thiện data, model, monitor, ta chỉ cần tập trung cải thiện ở step liên quan thay vì phải quan tâm đến toàn bộ pipeline
Kedro
Kedro là một opensource framework hỗ trợ xây dựng pipeline cho DS, giúp xây dựng pipeline, tạo sẵn cấu trúc cơ bản cho một project DS giảm thời gian phát triển, có khả tái sử dụng code, dễ maintain. Một số đặc điểm của kedro:
- Reproducibility: Kedro tạo ra các pipeline có khả năng triển khai và tái sử dụng trên các nền tảng khác như như windows, mac, linux do có thể cài đặt bằng các install package python.
- Modularity: Chia code thành các phần nhỏ, mỗi phần có trách nhiệm riêng giúp dễ đọc và dễ maintain.
- Maintainability: Kedro tạo ra một template chung cho các project giúp lập trình việc dễ tiếp cận với bất kì project nào và không cần phải viết lại các thành phần cơ bản của project nhiều lần.
- Versioning: Kedro cung cấp tính năng tracking dữ liệu, cấu hình các phiên bản cho pipeline để dễ quản lí, đánh giá.
- Documentation: Code được hỗ trợ bổ sung documentation tương ứng dễ đọc dễ hiểu.
- Seamless packagling: Các project tạo bảng kedro có khả năng tích hợp với các công cụ khác để triển khai như airflow, docker.
Kedro catalog
Kedro cung cấp một khái niệm gọi là catalog, đây là nơi lưu trữ thông tin của tất cả các nguồn dữ liệu được sử dụng trong project. Catalog được lưu trữ dưới dạng file catalog.yaml trong thư mục config với các trường biểu diễn loại thông tin, kiểu dữ liệu, đường dẫn đọc dữ liệu:
companies:
type: pandas.CSVDataset
filepath: data/01_raw/companies.csv
Ví dụ trên lưu thông tin của dữ liệu companies với các tham số để project có thể đọc dữ liệu này bao gồm:
- type: kiểu dữ liệu là csv. Kedro hỗ trợ config các kiểu dữ liệu xử lý bằng thư viện pandas hoặc matplotlib.
- filepath: đường dẫn đến folder chứa dữ liệu
- Ngoài ra còn một số các tham số khác như versioned, load_args, save_args, file_format,… tùy theo yêu cầu, xem chi tiết tại https://docs.kedro.org/en/stable/data/data_catalog_yaml_examples.html
Node and pipeline
Khi sử dụng kedro có 2 khái niệm cần nắm được để xây dựng project là node và pipeline
Node
Node là các khối thành phần bên trong một pipeline, tương ứng với các task. Pipeline kết nối các node lại với nhau tạo thành workflow từ đầu đến cuối. Mỗi node được đặt tên để dễ phân biệt các task của node với nhau. Node có thể được hiểu là các function thực hiện mỗi nhiệm vụ riêng như data processing, modelling.
from kedro.pipeline import node
Pipeline
Pipeline là luồng kết hợp các node lại với nhau. Một pipeline có nhiệm vụ cài đặt các dependency (các thư viện, cấu hình, dữ liệu) mà project cần để chạy, thứ tự thực hiện các node, kết nối input và output giữa các node. Thứ tự thực hiện các node trong một pipeline không cần thiết phải theo đúng thứ tự truyền vào pipeline. Có thể merge nhiều pipeline lại với nhau để được một pipeline lớn hơn. Mỗi pipeline con được gắn tags để phân biệt. Ví dụ tạo một pipeline tính sai số dự đoán, gắn tag cho pipeline tên là pipeline_variance:
def mean(xs, n):
return sum(xs) / n
def mean_sos(xs, n):
return sum(x**2 for x in xs) / n
def variance(m, m2):
return m2 - m * m
variance_pipeline = pipeline(
[
node(len, "xs", "n"),
node(mean, ["xs", "n"], "m", name="mean_node"),
node(mean_sos, ["xs", "n"], "m2", name="mean_sos"),
node(variance, ["m", "m2"], "v", name="variance_node"),
], tags="pipeline_variance"
)
Tham khảo chi tiết: https://docs.kedro.org/en/stable/nodes_and_pipelines/index.html
Setup
Kedro cung cấp cách cài đặt dưới dạng cài thư viện của python. Trước khi cài đặt kedro, ta cần đảm bảo cài sẵn git, python trên máy để tích hợp được kedro.
Cài đặt môi trường ảo
Đầu tiên ta cần cài môi trường ảo python dùng cho project của mình. Có thể sử dụng anaconda, pipvenv,… Ở đây ta sử dụng anaconda để tạo một môi trường ảo (trong windows cần mở của số Anaconda Powershell Prompt)
conda create --name kedro python==3.10
Init môi trường vừa tạo:
conda activate kedro
Trên trang chính thức của kedro, các phiên bản python đang hỗ trợ >3.8. Sau khi tạo môi trường xong, ta cần cài thư viện kedro:
pip install kedro
Ngoài ra một số phiên bản có thể cần cài đặt thêm thư viện kedro-viz (trường hợp khi cài kedro chưa có thư viện kedro-viz đi kèm). Đây là thư viện dùng để mô phỏng cấu trúc các thành phần bên trong project được tạo.
pip install kedro-viz
Khởi tạo project
Để khởi tạo một project kedro ta sử dụng lệnh kedro new.
kedro new --name=first_project --tools=lint,docs --example=n
Trong câu lệnh trên còn có các option khác kedro cung cấp để customize thêm cho project:
- –name: Tên của project, sau khi chạy, kedro sẽ tạo ra một thư mục tên là first_project
- –tools: Kedro cung cấp thêm các công cụ hỗ trợ sau
- lint: công cụ format code đúng chuẩn
- test: công cụ hỗ trợ viết test code
- log: ghi log trong project thay thế cho lệnh print
- docs: cài đặt thêm documentation cho code, giúp code dễ đọc mục đích của các hàm, dễ maintain
- data folders: bổ sung 1 folder để quản lí data
- pyspark: cấu hình thêm thư viện để chạy project sử dụng pyspark
- kedro viz: tool dùng để mô tả cấu trúc code
- –example: Bổ sung ví dụ code, dữ liệu khi mới bắt đầu với kedro.
Sau khi chạy lệnh trên, một thư mục tên là first_project được tạo với cấu trúc bên trong thư mục như sau:
- conf: Chứa các file config cho project như user, password, tham số model input.
- data: Thư mục chứa input, output data. Bên trong thư mục này được chia thành 9 thư mục con-layer (có thể thay đổi theo phiên bản kedro) để phân loại các loại data theo mục đích bao gồm:
- 01_raw
- 02_intemidiate
- 03_primary
- 04_feature
- 05_model_input
- 06_models
- 07_model_output
- 08_reporting
- 09_tracking
- docs: Chứa các file liên quan đến project documentation
- logs: Chứa các file ghi log của project khi chạy
- notebooks: Chứa các file notebooks được sử dụng trong project như đánh giá, EDA dữ liệu
- src: Chứa source code của project bao gồm các hàm data processing, model training, pipeline
First project
Để áp dụng các tính năng mà kedro cung cấp ở trên và hiểu được ưu điểm của việc sử dụng kedro trong các project data science, ta sẽ thử làm một project phát hiện bất thường trong dữ liệu sử dụng kedro framework.
Bước 1: Cài đặt môi trường và khởi tạo project
Ta vẫn sử dụng conda để tạo một môi trường ảo tên là kedro-anomaly-detection dành riêng cho project này, sử dụng phiên bản python 3.10 và active môi trường này:
conda create --name kedro-anomaly-detection python==3.10
conda activate kedro-anomaly-detection
Cài đặt kedro:
pip install kedro kedro-viz
Khởi tạo một project dùng kedro, apply công cụ lint và docs để hỗ trợ chỉnh sửa code đúng chuẩn:
kedro new --name=anomaly_detection --tools=lint,docs --example=y
Sau khi chạy lệnh trên, kedro sẽ khởi tạo một project với thư mục tên anomaly_detection, bên trong chứa các thư mục con:
README.md conf data docs notebooks pyproject.toml requirements.txt src
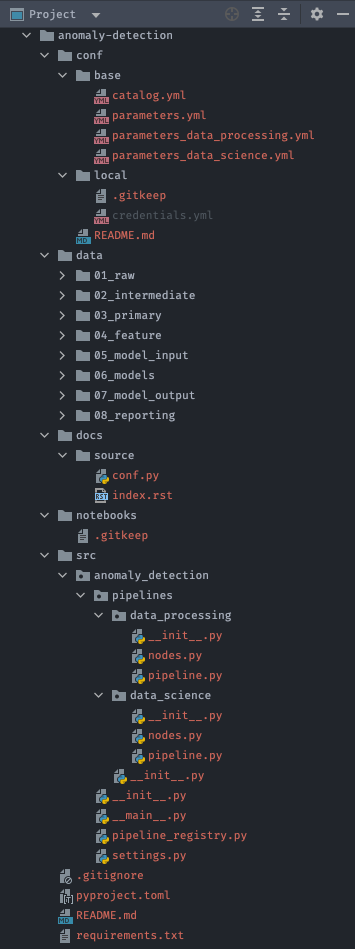
Kedro đã xây dựng sẵn một số thư viện cần thiết để bắt đầu project trong file requirements.txt, ta sẽ cài đặt các thư viện này vào trước khi bắt đầu xây dựng pipeline:
pip install -r requirements.txt
Bước 2: Data setup
Tiếp theo, ta sẽ setup thông tin catalog để định nghĩa tất cả các luồng data mà project sử dụng. Trong project này file catalog.yml sẽ gồm các file data sau:
raw_daily_data:
type: PartitionedDataSet
path: data/01_raw
dataset: pandas.CSVDataSet
layer: raw
merged_data:
type: pandas.CSVDataSet
filepath: data/02_intermediate/merged_data.csv
layer: intermediate
processed_data:
type: pandas.CSVDataSet
filepath: data/03_primary/processed_data.csv
layer: primary
train_data:
type: pandas.CSVDataSet
filepath: data/05_model_input/train.csv
layer: model_input
test_data:
type: pandas.CSVDataSet
filepath: data/05_model_input/test.csv
layer: model_input
Nhìn vào file catalog.yml trên, có thể hình dung được luồng của dữ liệu sẽ đi từ việc đọc data raw trong thư mục data/01_raw, sau đó tổng hợp lại vào một file gọi là merged_data.csv, tiếp đó được xử lý và đưa vào train model. Kiểu của file dữ liệu là file csv.
Bước 3: Tạo pipeline
Project dự đoán anomaly data được chia thành 3 module nhỏ, mỗi module là 1 pipeline:
- Data engineering pipeline
- Data science pipeline
- Model evaluation pipeline
Ở bước 1 khi khởi tạo project, ta chọn option example=y thì kedro sẽ tạo sẵn 2 pipeline data engineering và data science làm ví dụ rồi. Giờ ta chỉ cần tạo thêm pipeline model evaluation. Để tạo một pipeline mới ta chạy lệnh sau (mở Terminal /Command Prompt/Anaconda Powershell Prompt trong thư mục project):
kedro pipeline create model_evaluation
Để tạo pipeline khác, ta chỉ cần dùng lệnh:
kedro pipeline create pipeline_name
Lúc này, bên trong thư mục pipelines một thư mục tên là model_evaluation được tạo tương ứng với pipeline. 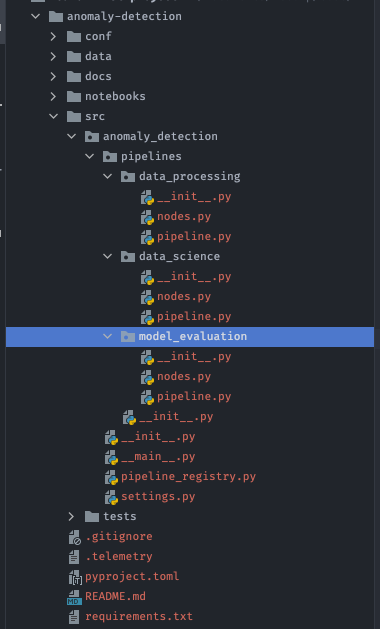
Bước 4: Tạo data engineer pipeline
Bước tiếp theo, ta cần xây dựng data engineer pipeline với mục đích biến dữ liệu raw thành dữ liệu có thể đưa vào model training ở bước tiếp theo. Pipeline này gồm 3 phần:
- Merge các file nhỏ thành một file data lớn
- Xử lý file data vừa tạo, chia dữ liệu thành phần dữ liệu cần dự đoán và dữ liệu dùng để training model
- Chia dữ liệu training thành 2 tập train và test theo tỉ lệ 80:20
Mỗi phần trong pipeline được viết thành 1 hàm, tương ứng với một node như sau:
from typing import Any, Callable, Dict, List
from datetime import timedelta, datetime
import pandas as pd
def merge_data(partitioned_input: Dict[str, Callable[[], Any]]) -> pd.DataFrame:
"""
Merge raw datasets into an intermediate merged dataset
Args:
partitioned_input:
Returns:
"""
merged_df = pd.DataFrame()
for partition_id, partition_load_func in sorted(partitioned_input.items()):
partition_data = partition_load_func()
merged_df = pd.concat([merged_df, partition_data], ignore_index=True, sort=True)
return merged_df
def process_data(merged_df: pd.DataFrame, predictor_cols: List) -> pd.DataFrame:
"""
Process merged dataset by keeping only the predictor columns and creating a new date column
for subsequent train-test split
Args:
merged_df:
predictor_cols: list predictor columns
Returns:
"""
merged_df['TX_DATE'] = pd.to_datetime(merged_df['TX_DATETIME'], infer_datetime_format=True)
merged_df['TX_DATE'] = merged_df['TX_DATETIME'].dt.date
processed_df = merged_df[predictor_cols]
return processed_df
def train_test_split(processed_df: pd.DataFrame):
"""
Perform chronological 80/20 train-test split and drop unnecessary column
Args:
processed_df:
Returns:
"""
processed_df['TX_DATE'] = pd.to_datetime(processed_df['TX_DATE'], infer_datetime_format=True)
split_date = processed_df['TX_DATE'].min() + timedelta(days=7*8)
train_df = processed_df.loc[processed_df['TX_DATE'] <= split_date]
test_df = processed_df.loc[processed_df['TX_DATE'] > split_date]
train_df.drop(columns=['TX_DATE'], inplace=True)
test_df.drop(columns=['TX_DATE'], inplace=True)
if 'TX_FRAUD' in train_df.columns:
train_df = train_df.drop(columns=['TX_FRAUD'])
if 'TX_FRAUD' in test_df.columns:
test_labels = test_df[['TX_FRAUD']]
test_df = test_df.drop(columns=['TX_FRAUD'])
else:
test_labels = pd.DataFrame() # empty dataframe if no test label
return train_df, test_df, test_labels
Sau khi tạo các node, ta sẽ kết hợp các node lại thành data engineering pipeline cho việc xử lý dữ liệu:
from kedro.pipeline import Pipeline, node, pipeline
from .nodes import merge_data, process_data, train_test_split
def create_pipeline(**kwargs) -> Pipeline:
return pipeline(
[
node(
func=merge_data,
inputs="raw_daily_data",
outputs="merged_data",
name="node_merge_raw_daily_data",
),
node(
func=process_data,
inputs=["merged_data", "params:predictor_cols"],
outputs="processed_data",
name="node_process_data",
),
node(
func=train_test_split,
inputs="processed_data",
outputs=["train_data", "test_data", "test_labels"],
name="node_train_test_split"
),
]
)
Mỗi node được tạo bằng cách sử dụng hàm node trong thư viện kedro.pipeline. Các tham số truyền vào hàm node bao gồm:
- func:
- inputs:
- outputs:
- name: