Causal Machine Learning
- 13 mins(draft)
Thực tế đánh giá thử nghiệm
Trong các môi trường phức tạp, causal ml là một công cụ mạnh mẽ và linh hoạt hơn so với A/B testing, bởi vì causal ml không đòi hỏi nhiều giả thuyết phức tạp.
Một câu hỏi có thể gặp phải ở rất nhiều công ty: Khi thay đổi một tính năng, liệu rằng, người dùng có phản ứng tích cực với tính năng mới này hay sẽ thích tính năng cũ hơn.
Khi cần thử nghiệm và đánh giá các thay đổi trên sản phẩm, ta thường nghĩ ngay đến a/b testing. Tuy nhiên, các thử nghiệm a/b test cần thêm một số yêu cầu về giả thuyết như trong cùng một thời điểm không nên chạy quá nhiều thử nghiệm. Với yêu cầu phát triển đáp ứng nhu cầu người dùng liên tục, rất khó để đảm bảo việc môi trường xung quanh thử nghiệm là không thay đổi.
Một công cụ khác có thể được sử dụng để đánh giá, trả lời câu hỏi “liệu rằng A sẽ tốt hơn B?” thay thế cho a/b testing đó là causal machine learning (causal ml). Phương pháp này có thể lợi thế về sự linh hoạt khi sử dụng, đặc biệt, khi người sử dụng nó chưa thể nắm bắt và điều khiển toàn bộ quy trình vận hành để đảm bảo điều kiện cần thiết cho việc tiến hành a/b testing.
Ví dụ: Có 4 user sử dụng sản phẩm của một hãng nước hoa, bài toán đặt ra cần đánh giá xem việc tặng các user này mã giảm giá có kích thích họ bỏ tiền ra mua sản phẩm hay không. Tưởng tượng bạn đang xem phim Doctor Strange, ta có thể quan sát hành vi của tất cả các user trong 2 vũ trụ song song, hoặc tất cả user đều được giảm giá hoặc tất cả user đều không được giảm giá. Giả thuyết rằng trước đó môi trường trải nghiệm sản phẩm của các user là không thay đổi, như các dòng sản phẩm, mùi hương,…
Ở vũ trụ đầu tiên, các user được giảm giá và đã bỏ ra 140$ để mua sản phẩm. Đối với vũ trụ còn lại, không có mã giảm giá nào và tổng số tiền mà các user bỏ ra là 100$. Dễ nhận thấy, trung bình mỗi user đang bỏ ra thêm 10$ để mua sản phẩm khi được cung cấp mã giảm giá. Do đó, việc cung cấp mã giảm giá đến user có thể làm tăng doanh thu cho công ty.
Trong thực tế, ta không thể quan sát thử nghiệm ở 2 vũ trụ như phim được. Đó là lí do cần tìm đến các phương pháp thử nghiệm khác để đánh giá. A/B testing là một cách phổ biến được sử dụng.
Một thử nghiệm sử dụng A/B test sẽ chia user thành các tập khác nhau trong cùng một môi trường. Một tập được gọi là treatment group và tập còn lại được gọi là control group. Các user thuộc tập treatment group sẽ được thử nghiệm mã giảm giá, trong khi, tập còn lại thì không có gì. Trong điều kiện lí tưởng, 2 tập user này là độc lập với nhau và việc đánh giá kết quả cũng tương tự như trong phim.
Vậy nhược điểm của A/B testing trong trường hợp này là gì?
Như hình trên, sau khi hết thời gian thử nghiệm, mỗi user ở tập treatment group cũng bỏ ra thêm 5$ để order sản phẩm. Điều này cũng cho thấy việc cung cấp mã giảm giá là có hiệu quả. Vậy có điều gì không đúng ở đây? Câu trả lời là không có gì cả cho đến khi… có quá nhiều thử nghiệm cùng xảy ra. Như đã nói ở trên, một trong những điều kiện của A/B testing để đảm bảo thu được kết quả tốt là không có quá nhiều A/B test xảy ra cùng lúc. Điều này sẽ khiến các test có thể ảnh hưởng lẫn nhau và làm sai lệch kết quả đánh giá. Trong thực tế, để đảm bảo các điều kiện lí tưởng này là vô cùng khó do yêu cầu phát triển nhanh và liên tục trên rất nhiều thành phần khác nhau; sai xót, xung đột trong việc phối hợp các team làm ảnh hưởng đến chất lượng báo cáo của DS/DA.
Causal machine learning - Causal ML
Để ứng phó với các điều kiện và quy trình phát triển phức tạp, ta cần tìm một phương pháp khác để hỗ trợ hay thay thế A/B testing, một trong số đó là causal machine learning. Đây là phương pháp suy luận áp dụng các thuật toán machine learning vào đánh giá chất lượng của thử nghiệm. Causal ML ước tính hiệu quả của thay đổi xảy ra với các user có thuộc tính (tập các thuộc tính) từ dữ liệu quan sát được mà không cần các giả thuyết quá chặt chẽ.
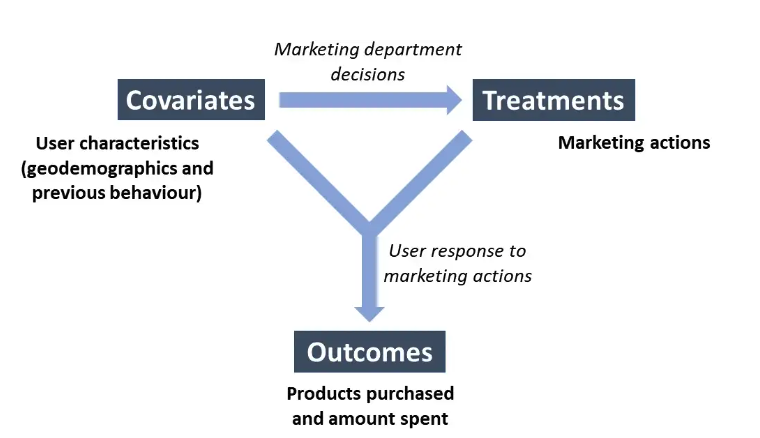
Hình trên mô tả sơ đồ hoạt động của một quy trình đánh giá thử nghiệm. Quy trình này có 3 thành phần chính:
- Covariates là tập các đặc điểm của user (ngoại trừ treatment - các đặc điểm mà chúng ta muốn thử nghiệm trên user như cung cấp mã giảm giá) của user trong tập được chọn. Dữ liệu này được thu thập trước khi thử nghiệm, để theo dõi tác động thu được trước và sau khi áp dụng thay đổi hoặc ảnh hưởng của thử nghiệm lên các đặc điểm hành vi khác nhau (sự biến thiên của các đặc điểm khác sẽ đồng biến hay nghịch biến)
- Treatments là hành vi mà chúng ta muốn thử nghiệm trên user (mã giảm giá)
- Outcomes là kết quả nhận được
Ta sử dụng dataset mẫu có dạng như sau: 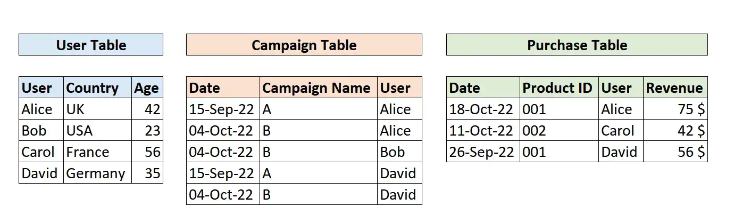
- Bảng User chứa các đặc điểm của user (covariates)
- Bảng Campaign chứa thông tin của các chiến dịch thử nghiệm dành cho từng user (treatments)
- Bảng Purchase lưu các thông tin về kết quả thu được (outcomes)
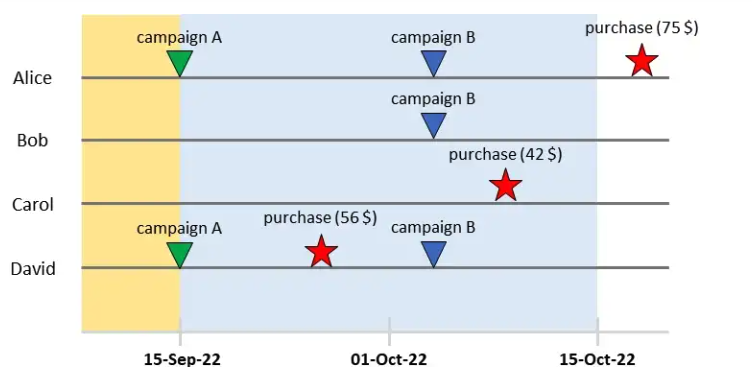
Toàn bộ quá trình thử nghiệm được minh hoạ lại theo sơ đồ dưới đây: 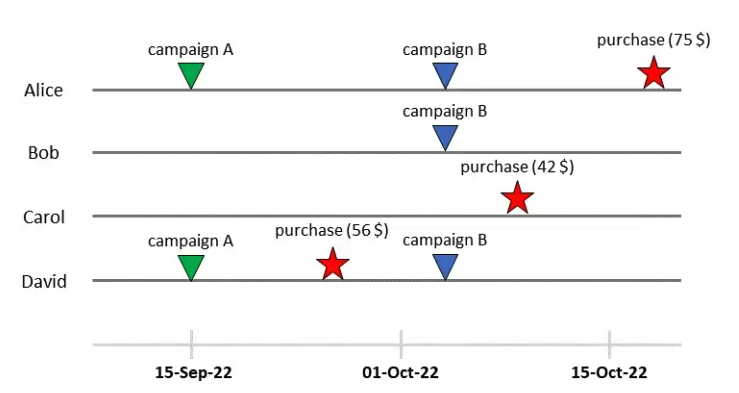
Hãy nhìn vào Alice. User này nằm trong 2 chiến dịch: A (ngày 15/9) và B (ngày 4/10). Alice đã thanh toán tổng cộng 75$ vào ngày 18/10. Nhìn vào dữ liệu này có một số câu hỏi cần trả lời:
- Làm thế nào để biết được Alice quyết định bỏ tiền ra vì chiến dịch A hay B hay do tác động từ cả 2 chiến dịch kết hợp lại?
- Nếu không tham gia bất kì chiến dịch nào thì Alice có bỏ tiền ra cho sản phẩm không?
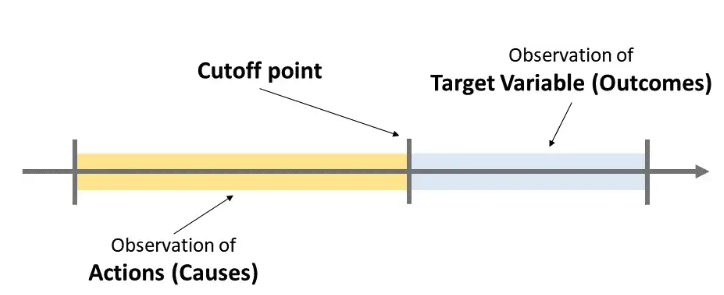
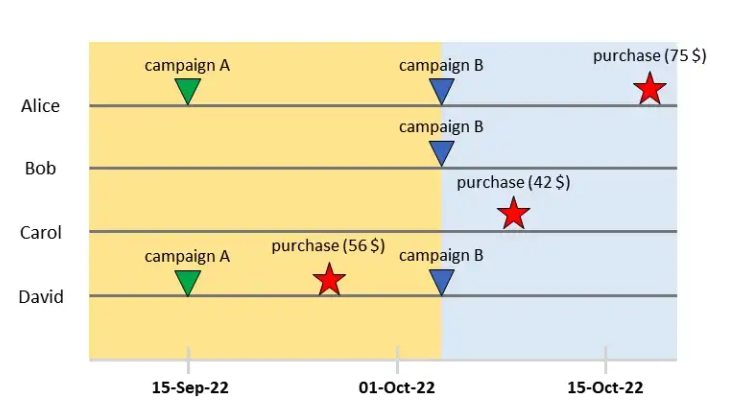
Để áp dụng causal ml, ta chọn một thời điểm gọi là cutoff point, chia dataset thành 2 phần:
- Actions (causes): Các hành động xảy ra trước thời điểm cutoff point
- Target variable (outcomes): Các hành động xảy ra sau thời điểm cutoff point
Với giả sử rằng, các hành động action là nguyên nhân gây ra target. Ở đây, ta chưa đề cập đến việc lựa chọn thời điểm cutoff như thế nào, điều này phụ thuộc vào thời gian muốn đánh giá và điều kiện thực tế. Để đơn giản, ta chọn thời gian actions và target đều kéo dài 1 tháng. Thời gian đánh giá kết quả bây giờ kéo dài từ 15/9 đến 15/10, cutoff point từ ngày 15/9 khi bắt đầu chiến dịch A. Mục đích cuối cùng của ta sẽ là đánh giá về outcome thu được. ……….. Thời điểm cutoff point là linh hoạt nên ta có thể chọn một thời gian khác như thời gian bắt đầu chiến dịch B ngày 4/10.
Bây giờ ta tổng hợp và chia dữ liệu thành 2 tập X và Y: 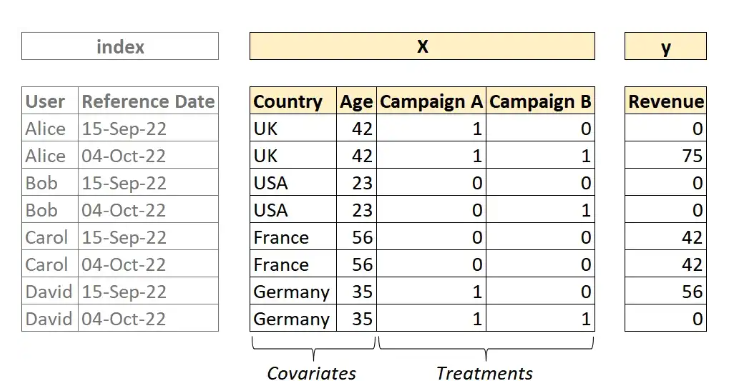
Đến đây, chắc nhiều người sẽ hình dung ra việc sử dụng causal machine learning như thế nào. Tập X (features) gồm 2 phần: covariates (các đặc điểm của user) và treatments (user tham gia vào chiến dịch nào). Tập Y (target) là kết quả thu được. Sau khi xử lý lại dataset, bài toán sẽ được quy về việc áp dụng thuật toán machine learning vào để dự đoán. Ưu điểm của cách làm này so với việc sử dụng A/B testing đó là các model machine learning có thể học được mối quan hệ giữa treatment và covariate. Trong dataset này, model sẽ học được ảnh hưởng giữa các đặc điểm của user đến từng chiến dịch. A/B testing chỉ cung cấp đánh giá tương quan giữa treatment và target thử nghiệm.
Nhắc lại một chút ở bên trên, ta không thể quan sát các vũ trụ song song như DS (Doctor Strange) để đánh giá nhưng các DS (data scientist) có thể mô phỏng lại các vũ trụ này bằng cách sử dụng causal ML:
- Vũ trụ A: User không tham gia bất kì chiến dịch nào
- Vũ trụ B: User tham gia các chiến dịch thử nghiệm
Với mỗi vũ trụ, ta cần xây dựng lại dataset cho phù hợp để tạo ra 2 dataset mới (chuyển các biến treatment băng 0 nếu user không tham gia). Lưu ý không thay đổi các biến covariate.
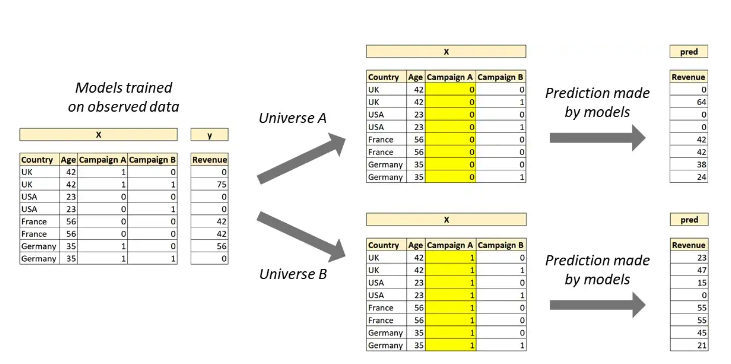
Trong dataset vừa xây dựng lại, ta chỉ cần thay đổi treatment cho phù hợp. Bằng cách này, có rất nhiều kịch bản khác nhau có thể cùng được thử nghiệm và đánh giá.
Một vấn đề xảy ra với tập dữ liệu này. Thời gian thử nghiệm có thể ngắn hoặc dài tùy điều kiện, điều đó dẫn đến kích thước dữ liệu có thể hạn chế. Ngoài ra, việc không thay đổi các đặc điểm (covirate) thì dự đoán của các model với mỗi kịch bản có thể giống nhau, dẫn đến đánh giá không hiệu quả. Để giải quyết vấn đề này, ta sẽ liên tưởng đến một phương pháp khác đó là cross-validation.
Cross-validation là phương pháp được sử dụng khi bị hạn chế về lượng dữ liệu để huấn luyện. Khi huẩn luyện ta thường tách một phần tập dữ liệu training làm tập validation. Vấn đề khi dữ liệu bị hạn chế, kích thước tập validation quá nhỏ (dễ gây ra overfit) hoặc tập training không đủ để huấn luyện. Một cách sử dụng cross validation là chia tập training thành k tập nhỏ kích thước bằng nhau, không có điểm chung. Tại mỗi lượt training (gọi là fold), một trong số k tập được chia ra ở trên được chọn làm tập validation và k-1 tập còn lại dùng làm tập training.
Áp dụng ý tưởng của cross validation, với mỗi kịch bản ta sẽ chia lại tập dữ liệu training tương ứng và thực hiện huấn luyện model nhiều lần.
Bây giờ ta thử huấn luyện model để trả lời cho câu hỏi: Chiến dịch A có đem lại hiệu quả hay không?
Đầu tiên, ta thực hiện huấn luyện cho từng dataset đã xây dựng ở trên:
import pandas as pd
from sklearn.model_selection import KFold
from lightgbm import LGBMRegressor
# Số lượng fold
n_folds = 5
# Lưu trữ model huấn luyện được với mỗi fold
folds = {fold: dict() for fold in range(n_folds)}
# Huấn luyện model
for fold, (ix_train, ix_test) in enumerate(KFold(n_splits=n_folds).split(X=X)):
folds[fold]["ix_test"] = ix_test
folds[fold]["model"] = LGBMRegressor().fit(
X=X.loc[ix_train, :],
y=y.loc[ix_train]
)
Sau khi đã huấn luyện xong các model, ta sẽ sửa lại dữ liệu tương ứng với 2 kịch bản:
- Tất cả user tham gia chiến dịch A
- Tất cả user không tham gia chiến dịch A
X_zeros = X.replace({"campaign_A": {1: 0}})
X_ones = X.replace({"campaign_A": {0: 1}})
pred_zeros = pd.Series(index = X.index)
pred_ones = pd.Series(index = X.index)
for fold in folds.keys():
ix_test = folds[fold]["ix_test"]
model = folds[fold]["model"]
pred_zeros.loc[ix_test] = model.predict(X_zeros.loc[ix_test, :])
pred_ones.loc[ix_test] = model.predict(X_ones.loc[ix_test, :])
Kết quả thu được:
- pred_ones: Hiệu quả khi tất cả user tham gia chiến dịch A
- pred_zeros: Hiệu quả khi tất cả user không tham gia chiến dịch A
Bây giờ ta so sánh kết quả thử nghiệm 2 kịch bản:
outcomes = (pred_ones - pred_zeros).mean()
Ví dụ trên chỉ là một bài toán giả định nhỏ để minh họa cách áp dụng causal ml trong việc đánh giá các thử nghiệm. Outcome ở đây có thể được định nghĩa bằng các giá trị nhị phân (đại diện cho các hành động khác nhau như mua hay không mua, click hay không click,…). Ngoài ra trong các trường hợp xây dựng lại dataset cho phù hợp với mỗi kịch bản cần sử dụng phân phối xác suất cho phù hợp với thực tế.
A/B testing là một phương pháp phổ biến, đơn giản để áp dụng, đánh giá các thử nghiệm đối với các bài toán. Tuy nhiên trong nhiều trường hợp với các điều kiện phức tạp, cần linh hoạt so sánh các kịch bản khác nhau, causal ml là một phương pháp hữu ích có thể được sử dụng thay thế.
HN, 2022/12/04!