Apache Doris
- 6 minsApache doris
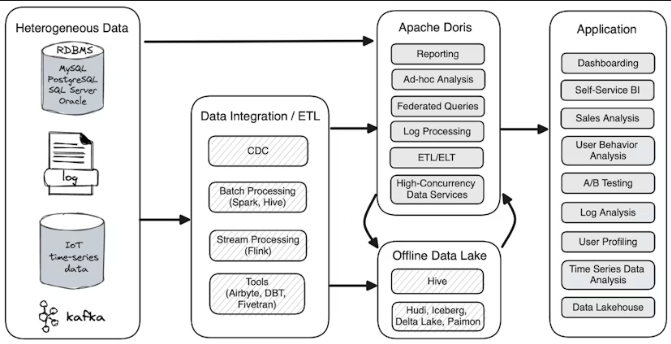
Apache doris là một open-source, real-time data warehouse. Chức năng của doris có thể thu thập dữ liệu từ các nguồn khác nhau, như mysql, postgresql, logs, hỗ trợ reporting, ad-hoc analysis, federated queries, log analysis dùng cho các nghiệp vụ BI, A/B testing, phân tích hành vi người dùng,…
Doris hỗ trợ cả ghi dữ liệu theo batch và stream, tích hợp vào các công cụ khác như spark, hive, flink, iceberg.
Architectural design
Tiếp theo ta sẽ đi sâu vào kiến trúc của doris, các tính năng và cơ chế hoạt động để doris có thể đạt được hiệu năng tốt.
- Cost-based optimizer (CBO): Doris tối ưu chi phí cho các query nặng, phức tạp. Doris sử dụng fully vectorized execution để giảm các lần gọi virtual function và cache miss.
- Massively parallel processing (MPP-based): Tận dụng tài nguyên các core của máy. Trong apache doris, các query thực hiện theo nguyên tắc data-driven, nghĩa là một query được thực hiện khi data nó sử dụng sẵn sàng, từ đó giúp cho việc sử dụng CPUs hiệu quả hơn
Fast point queries for a columnd-oriented database
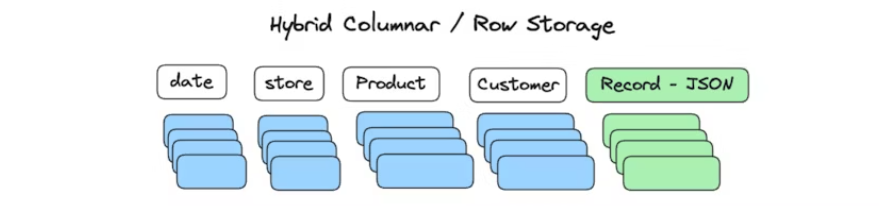
Doris là một column-oriented database (database hướng cột) giúp cho việc nén dữ liệu và sharding dễ dàng và nhanh chóng hơn. Tuy nhiên việc này cũng có nhược điểm khi cần query liên tục do có thể làm tăng I/O đến một cột nào đó trong bảng (high-concurrency point queries).
Để xử lý vấn đề này, doris sử dụng một kĩ thuật là hybrid storage, có nghĩa là sử dụng cả row storage (record json) và column storage cùng lúc.
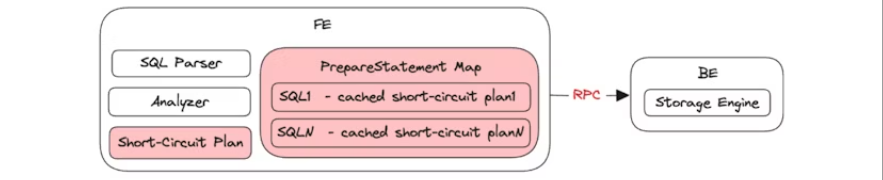
Ngoài ra, khi thực hiện các truy vấn đơn giản, thay vì sử dụng query planner để phân tích câu truy vấn, doris sẽ sử dụng khái niệm gọi là short circuit plan để giảm chi phí xử lý. Một thao tác tốn nhiều tài nguyên đó là SQL parsing. Do đó, doris chuẩn bị sẵn trong cache, nó tính toán trước sql statement và lưu lại để có thể tái sử dụng cho các query tương tự, giảm thời gian tính toán và chi phí.
Data ingestion
Doris cung cấp các method để tích hợp phục vụ cho data ingestion. Tùy theo yêu cầu bài toán, việc ingest data có thể xử lý theo batch hoặc stream:
Real-time streaming
-
Stream load:
-
Flink-doris-connector
-
Routine load:
-
Insert into: Method này dùng để chuyển dữ liệu (ETL), như chuyển dữ liệu giữa các bảng doris với nhau
Batch writing
-
Spark load
-
Broker load
-
Insert into: Method này với batch processing dùng để kết nối doris với các storage khác bên ngoài, data lake, database khác.
Data update
Khi update data, doris hỗ trợ cả merge on read (dùng khi update theo batch) và merge on write (dùng khi update real-time). Với merge on write, dữ liệu mới sẽ luôn sẵn sàng khi thực hiện truy vấn, còn đối với merge on read, dữ liệu mới sẽ được update chậm hơn. Một thao tác update dữ liệu doris hỗ trợ:
- Upsert: Thay thế, update toàn bộ row
- Partial column update: Update một hoặc một vài column của row
- Conditional update: Update data theo một điều kiện nào đó
- Insert overwrite: insert lại toàn bộ hoặc một phần của bảng
Doris cho phép user quyết định update theo thứ tự đã commit trong transaction hoặc update lần lượt theo từng cột trong bảng.
Service availability and data reliability
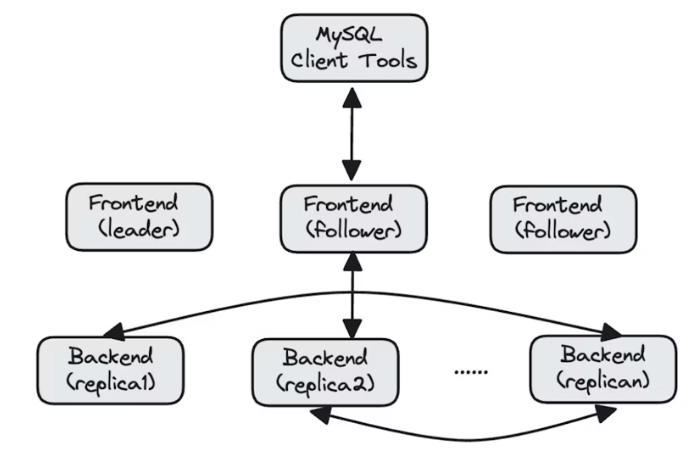
Doris cung cấp tính sẵn sàng và ổn định. Kiến trúc của doris gồm 2 phần: frontend và backend. Mỗi phần đều có khả năng scale. Các node frontend quản lí metadata và xử lý request của user. Các node backend thực hiện query có khả năng tự balancing và khôi phục khi có lỗi, hỗ trợ việc nâng cấp và scale tránh ảnh hưởng đến service cung cấp.
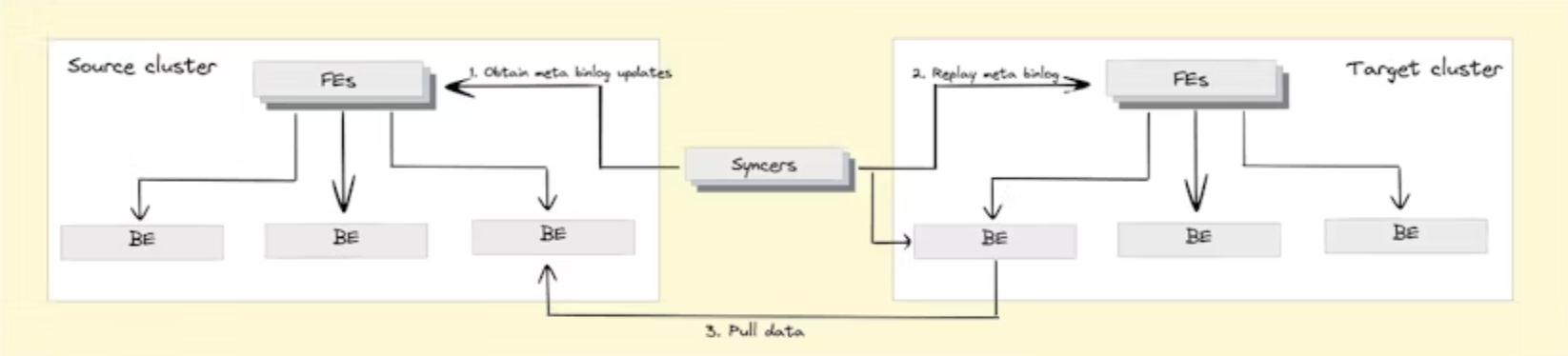
Cross cluster replication
Doris cung cấp tính năng cross cluster replication dùng để backup dữ liệu trong cluster với các đặc điểm:
- Disaster recovery: khôi phục nhanh dữ liệu
- Read-write separation: tách biệt xử lý các thao tác đọc ghi, sử dụng kiến trúc master-slave, một node để đọc, một node để ghi
- Isolated upgrade of clusters: Khi scale cluster, cross cluster replication cho phép user tạo một bản backup để chạy thử kiểm tra các lỗi có thể phát sinh trong quá trình nâng cấp
Cross cluster replication giúp việc nâng cấp ổn định hơn, có thể đạt được độ trễ khi nâng cấp trong vài phút.
Multi-tenant management
Apache doris cung cấp việc phân quyền truy cập cho user đến level từng database, table, row và column.
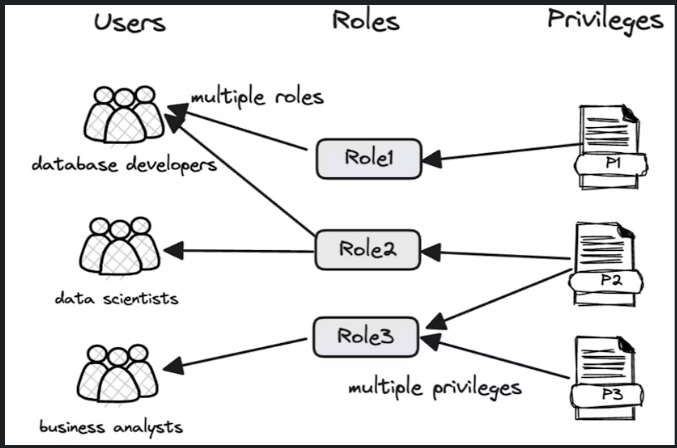
Doris sử dụng soft limit để quản lí các nhóm user, phân chia tài nguyên sử dụng
SQL suport
Doris hỗ trợ việc sử dụng thông qua SQL. Ngoài ra, doris cung cấp tính năng gọi là light schema change. Tính năng này hỗ trợ user khi cần thêm, xóa column trong bảng, chỉ cần update metadata ở frontend, không cần phải update toàn bộ data. Việc cập nhật bằng light schema change có thể thực hiện trong vài ms. Light schema change còn hỗ trợ thay đổi index, data type trong cột. LSC kết hợp với flink-doris-connector giúp đồng bộ upstream table tính bằng ms.
Semi-structured data analysis
Dữ liệu dạng semi-structured trong thực tế như log, time-series data. Để xử lý các dữ liệu này, database cần hỗ trợ schema-free, chi phí thấp, hỗ trợ phân tích, full-text search.
Một ví dụ về tìm kiếm text thường thấy là toán tử LIKE. Doris đẩy toán tử này xuống tầng storage để giảm việc scan dữ liệu, sử dụng các thuật toán n-gram bloomfilter, hyperscan regex matching và volnitsky.
Data lakehouse
Doris có thể map, cache, refresh metadata từ external source. Doris hỗ trợ hive metastore và hầu hết các data lakehouse format, có thể connect đến các relational database, elasticsearch,… Tái sử dụng lại các hệ thống authenication đang có như kerberos, apache ranger.
Tiered storage
Mục đích của tiered storage là giảm chi phí sử dụng. Tiered storage tách biệt hot data và cold data với nhau. Hot data là nhưng dữ liệu thường xuyên được truy cập. Các dữ liệu này được lưu ở SSD hoặc HDD. Cold data dược lưu trữ trong các object storage. Việc phân loại data lưu trữ vào các storage khác nhau giúp giảm chi phí do SSD hay HDD có chi phí vận hành cao hơn.